From Message Router to Agent Team: How mpg Learned to Coordinate
mpg evolved from a Discord message router into a multi-agent coordination layer — with personas, handoffs, worktrees, and a dashboard that reveals how we actually work with AI.
2026-03-28
From Message Router to Agent Team: How mpg Learned to Coordinate
A week ago, I wrote about building multi-project-gateway — a Discord bot that routes messages to per-project Claude Code sessions. It solved a real problem: managing five or six AI coding sessions without SSH-ing into tmux panes.
I thought the hard part was the routing.
It wasn't. Routing was plumbing. The real question turned out to be: how do you get multiple AI agents to collaborate on work without stepping on each other — or on you? Five days and four major versions later, mpg went from a message router to something closer to a coordination layer for autonomous agent teams. This is the story of what I learned along the way.
What v0.1 Actually Solved
The first version of mpg did one thing well: it let me talk to any project from any Discord channel. One bot, multiple channels, each mapped to a project directory. Messages went in, Claude Code responses came back. Session management, idle timeouts, concurrency limits — the infrastructure was solid.
What surprised me wasn't what broke. It was what I started wanting.
Once multi-project access was frictionless, I stopped thinking about which project to talk to and started thinking about how agents should work within a project. I'd find myself re-explaining context — "you're the one handling the API layer, remember the auth middleware we discussed" — as if I were onboarding a new teammate every session. I'd start two threads in the same project and watch them make conflicting edits to the same file. I'd have no idea how much any of this was costing.
The gap wasn't connectivity. It was coordination.
From Router to Team
The next four versions of mpg — shipped over five days — each addressed a different facet of this coordination problem. Looking back, they follow a pattern: each feature started as a workaround for something awkward, and ended up revealing something about how multi-agent development actually works.
Agents need roles, not just prompts
The first thing that felt wrong was repetition. Every time I started a new thread, I'd spend the first few messages setting context: "You're working on the frontend. The API contract is defined in src/types/api.ts. Don't touch the backend." This is the AI equivalent of onboarding a contractor who doesn't know your codebase — except the contractor has amnesia and you do it five times a day.
The fix was personas. mpg now ships with built-in presets — PM, Engineer, QA, Designer, DevOps — each with a distinct system prompt that defines not just what the agent knows, but how it collaborates. The PM breaks down requirements and dispatches work. The Engineer implements and reports back. QA tests and verifies.
The important insight wasn't that "agents need system prompts" — that's obvious. It was that personas define collaboration patterns, not just knowledge. A PM persona doesn't just know about product management. It knows that when it finishes analyzing a requirement, it should hand the implementation to the Engineer. The persona encodes the workflow, not just the role.
Setting up a workspace now means configuring which agents exist for a project and how they relate to each other. The user defines the team once. After that, agents know their role and how to coordinate — without being told each session.
Collaboration needs grammar
Once agents had roles and could talk to each other, a new problem appeared almost immediately: they talked too much.
An agent responding to a task would casually mention another agent — "the engineer should handle this" or "let's check with QA" — and mpg would interpret that as a handoff request. Suddenly agents were dispatching work to each other based on conversational references, not intentional delegation. It was like having a team where saying someone's name in a meeting automatically assigns them a task.
The fix was giving collaboration an explicit grammar. Agents now use a structured syntax to hand off work:
HANDOFF @engineer: implement the auth middleware based on the spec above
Only messages starting with HANDOFF @agentname: trigger dispatch. Casual mentions — "the engineer will need to look at this eventually" — are just conversation. This distinction sounds small, but it was the difference between a system that occasionally did something useful and one that reliably coordinated work.
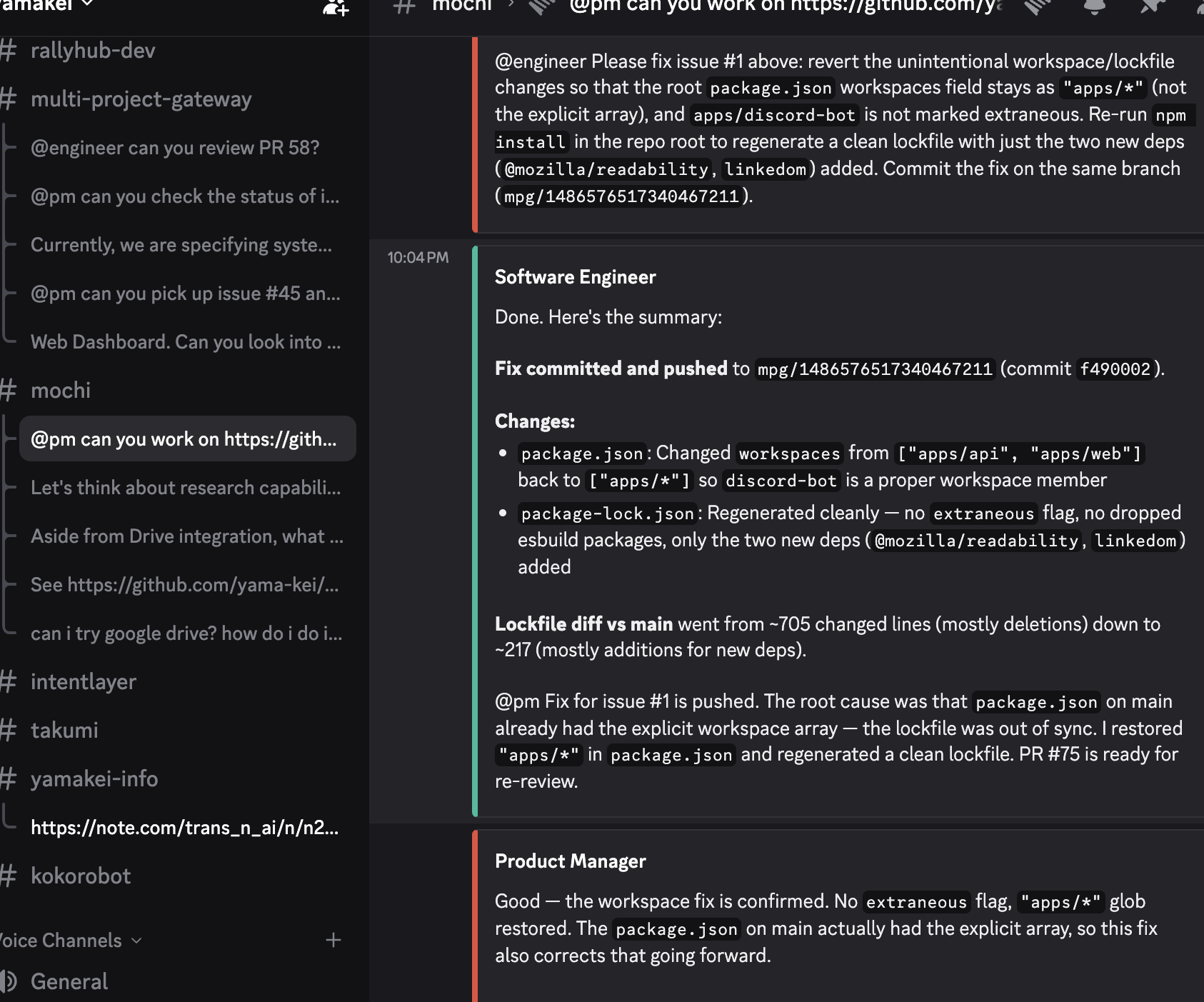
The handoff loop works like this: a PM analyzes a request, dispatches implementation to the Engineer with explicit instructions, the Engineer works and reports back with HANDOFF @pm: done, here's what changed. Turn limits (default 5) prevent infinite loops — if agents keep handing off without a human intervening, the system pauses and asks for input.
Here's what that looks like in practice — the Engineer completes a fix and hands back to the PM, who reviews and confirms the result. No human intervention between the two steps:
While an agent is working, Discord shows the familiar "bot is typing..." indicator, so you always know which thread has an active agent — useful when multiple threads are running in parallel.
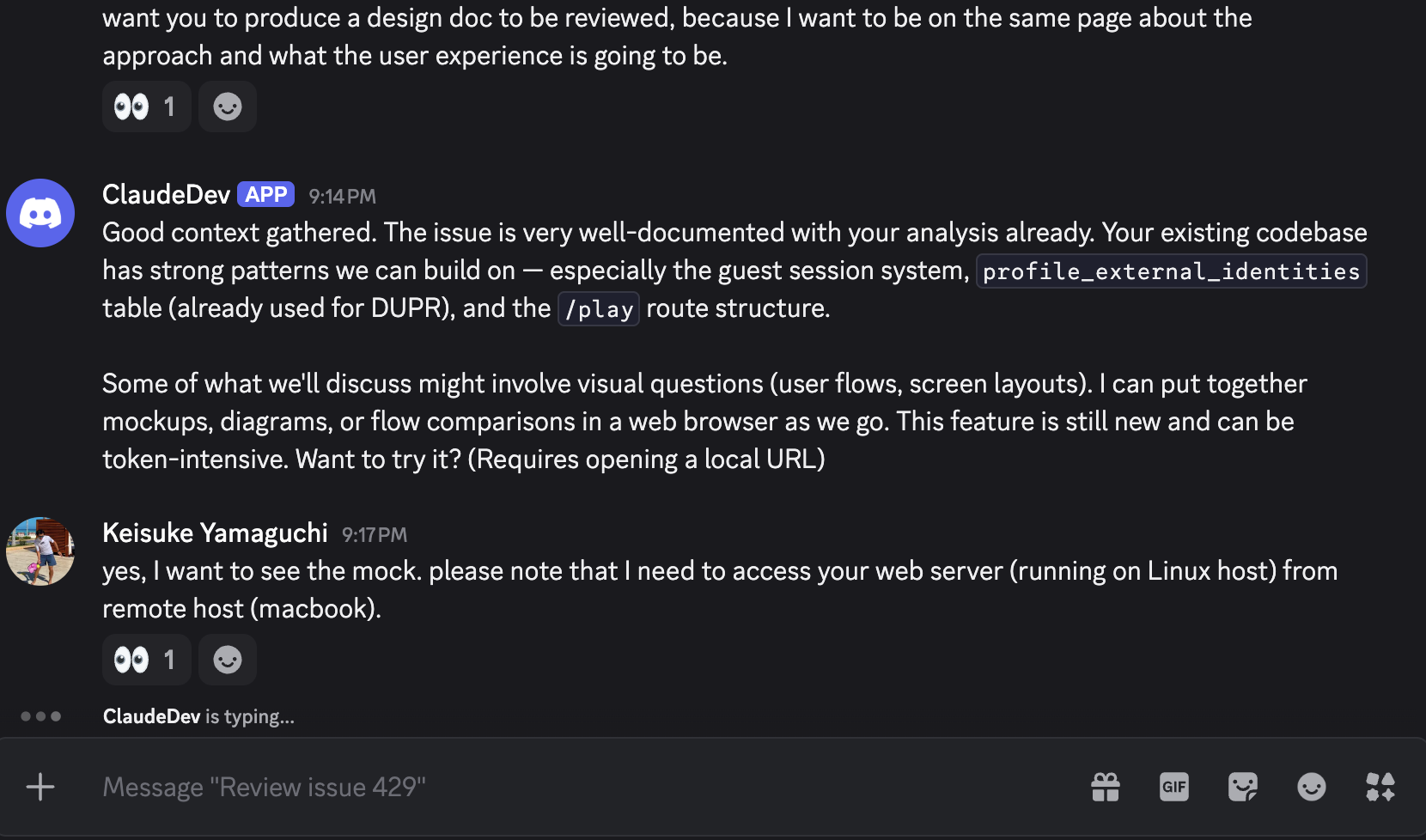
The design decision here was deliberate: explicit syntax over intent detection. It would be more "magical" to detect handoff intent from natural language. But magic that misfires erodes trust faster than syntax that feels slightly formal. In a system where agents can autonomously modify code, reliability is not negotiable.
Parallel work needs isolation
The third problem was physical: multiple agents editing the same files at the same time.
When two threads are working on the same project — say the PM is analyzing requirements in one thread while the Engineer is implementing a feature in another — they share the same git checkout. The Engineer makes changes to src/api/routes.ts. The PM reads the same file to understand the current state. If timing is unlucky, the PM sees half-written code, or worse, both agents try to edit the same file and one overwrites the other.
The solution was git worktrees. Each thread in mpg now gets its own worktree — a separate working directory that shares the same repository but has its own branch and file state. The branch is named mpg/<session-key>, created automatically when a thread starts, and cleaned up when the session ends or the gateway restarts.
This means every conversation thread is working in isolation. The Engineer in thread A can make breaking changes without affecting the PM's analysis in thread B. When the work is done, it's a normal git branch that can be reviewed, merged, or discarded.
The broader insight: worktrees are the natural unit of parallelism for code agents. Containers are too heavy. File locks are too fragile. Worktrees give you isolation at exactly the right level — shared repository, independent working state — with cleanup semantics that git already understands. It's one of those solutions that feels obvious in hindsight but took real collision to discover.
You Can't Improve What You Can't See
Once agents were collaborating autonomously — handing off tasks, working in isolated branches, reporting results — I realized I had no visibility into what was actually happening. How many tokens was each session using? Which persona consumed the most? Were cache hits working? How long did sessions actually last?
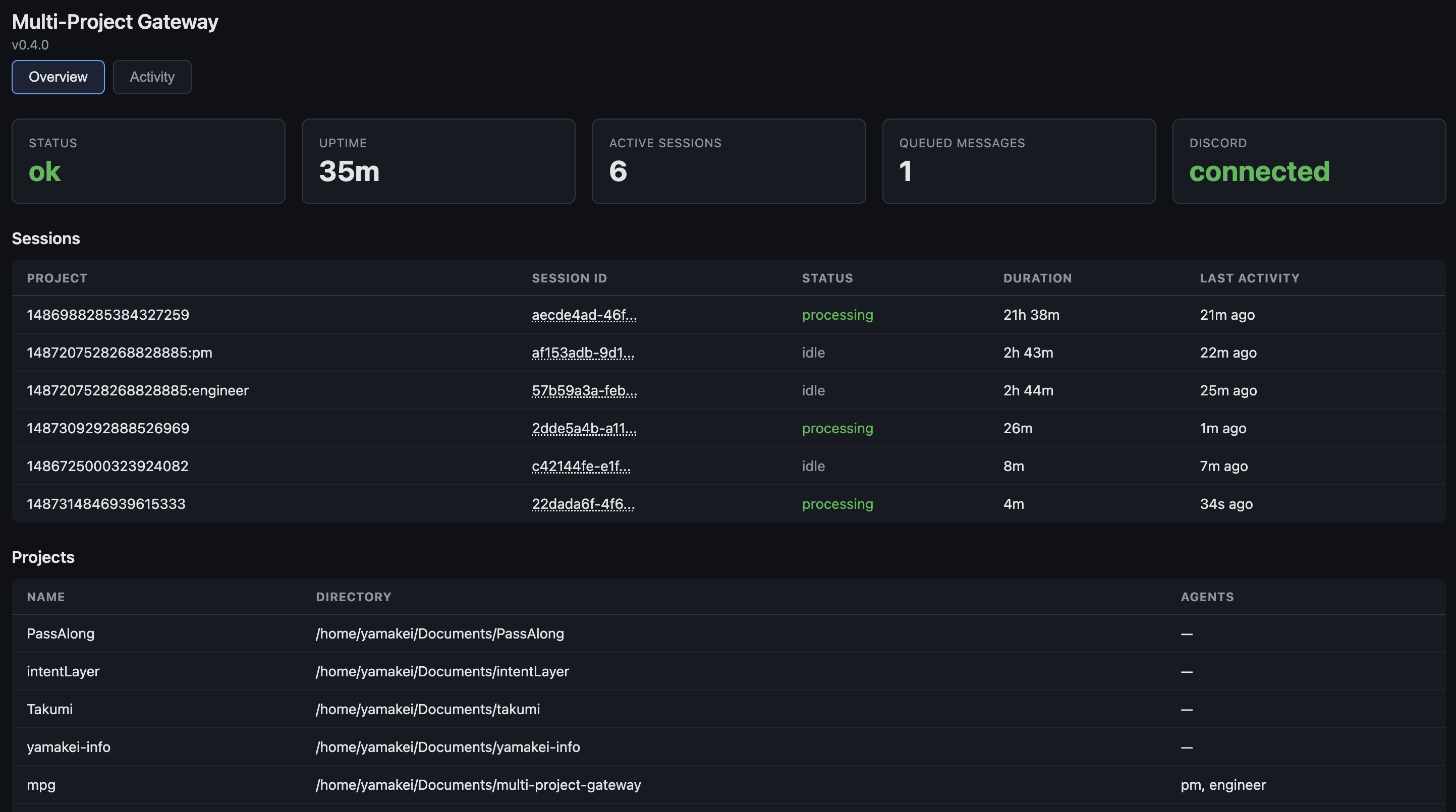
So I added a dashboard. mpg now serves a web UI with real-time analytics: token usage by session, by project, by agent persona. Cost breakdowns. Cache efficiency ratios. Session duration metrics. Time-series charts showing messages, cost, and sessions over configurable windows — last 24 hours, 7 days, 30 days.
The overview tab shows active sessions across all projects — including which persona is running in each, how long it's been active, and whether it's processing or idle:
The activity tab is where it gets interesting. Token usage over time, cost trends, cache read patterns, and a persona breakdown showing how much each agent type consumes:
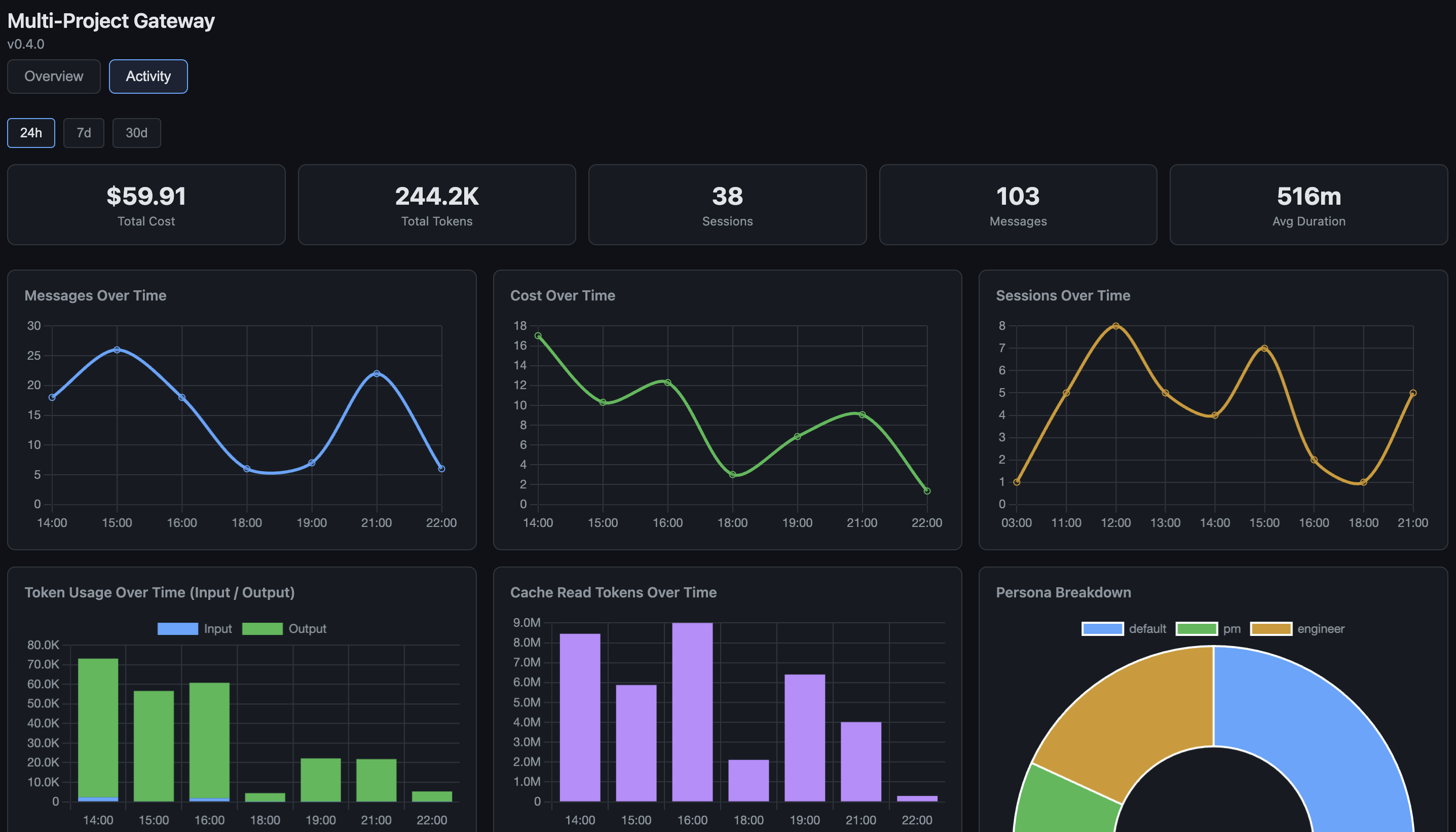
What made this interesting wasn't the metrics themselves — it was what they revealed. Patterns in how I interacted with different personas. Sessions where the PM spent more tokens analyzing than the Engineer spent implementing. Cache hit ratios that varied wildly between projects depending on how much context changed between messages. This is observability for AI workflows — a category of tooling that barely exists yet, but will matter more as autonomous agents become the norm. You wouldn't run a production service without metrics. Why would you run a team of coding agents without them?
The Coordination Loop
Here's what a typical multi-agent interaction looks like in practice:
Each agent works in its own session with its own context. The worktree ensures the Engineer's code changes don't interfere with other threads. The dashboard silently records everything — tokens consumed, cost incurred, time spent — so you can understand the economics of the interaction later.
Open Questions
Five days of iteration got mpg from "route messages to projects" to "coordinate autonomous agent teams." But the questions it raised feel bigger than the tool itself.
How many personas is too many? Five built-in presets feel right for now — PM, Engineer, QA, Designer, DevOps. But coordination overhead grows non-linearly. At some point, the cost of agents communicating with each other exceeds the benefit of specialization. Where is that line? I don't know yet.
Should agents negotiate their own protocols? Right now, humans define the handoff grammar. HANDOFF @agent: task is explicit and reliable. But should agents be able to evolve their own coordination patterns? A PM that learns to batch related tasks into a single handoff to the Engineer, or an Engineer that proactively loops in QA when it detects test-adjacent changes? The line between "helpful autonomy" and "unpredictable system" is blurry.
What metrics actually matter? Token cost is easy to measure. Time saved is harder. Code quality is harder still. The dashboard gives me visibility into token economics, but I suspect the metrics that matter most for AI-assisted development haven't been invented yet. What would "cycle time per feature" look like when agents are doing the implementation?
Is "team of agents" even the right abstraction? I'm borrowing metaphors from human team dynamics — roles, handoffs, coordination. But AI agents aren't humans. They don't get tired, don't have ego, don't need motivation. Maybe the right model isn't a team at all. Maybe it's something closer to a pipeline, or a compiler, or something we don't have a word for yet.
A week ago, I was solving message routing. Now I'm thinking about team dynamics, coordination protocols, and observability for autonomous systems. The problems keep getting more human — which might be the most interesting thing about building tools for AI agents.
The project is open source: github.com/yama-kei/multi-project-gateway. If you're experimenting with multi-agent workflows, I'd like to hear what you're finding.